只看名字会觉得 metadata 很像一个边角模块,像是给服务补一点描述信息、给注册中心多带几个参数。
但实际它上并不只是“保存元数据”,而是在应用级服务发现模型之上,补上了一层完整的语义解释能力。注册中心负责告诉框架“有哪些应用实例”,而 metadata 负责告诉框架“这些实例到底提供了什么服务”。
这篇文章不做逐行源码解析,而是比较宏观的从设计视角去梳理 dubbo-go 3.0 的 metadata 模块:它解决了什么问题、内部怎么组织、和其他模块怎么配合,以及为什么它会呈现出这样一套相对完整的形态。
文中讨论以 dubbo-go 3.0.x 这一代实现为主,这里主要对照 v3.0.5 / release-3.0 这条代码线,不混用后续 main 分支里继续演进出来的 metadata 能力。
为什么需要 Metadata(它解决了什么问题)
首先去查看它所处的服务发现背景
在接口级注册发现模型里,consumer 订阅某个接口,注册中心直接返回这个接口对应的一组 provider 地址。这个模型简单直接,因为“接口”和“地址”天然绑定。
但到了 dubbo-go 3.0,它更强调应用级服务发现。注册中心中更核心的对象不再是“某个接口的地址列表”,而是“某个应用的实例列表”。
这样一来,注册中心知道的是:
- 哪些应用实例在线
- 每个实例的地址是什么
- 每个实例是否健康
但 consumer 真正关心的是:
- 这个应用实例到底暴露了哪些接口
- 某个接口到底属于哪些应用
- 这些接口的 group、version、protocol、path、methods 是什么
- provider 的服务集合变化后,consumer 怎么感知
但这些问题注册中心本身不会去回答。
于是这时候为了解决这部分问题 metadata 出现了,成为应用级服务发现能够真正落地所必须的语义层。
所以简单的回答为什么需要 metadata:注册中心解决“找到实例”,metadata 解决“理解实例”。
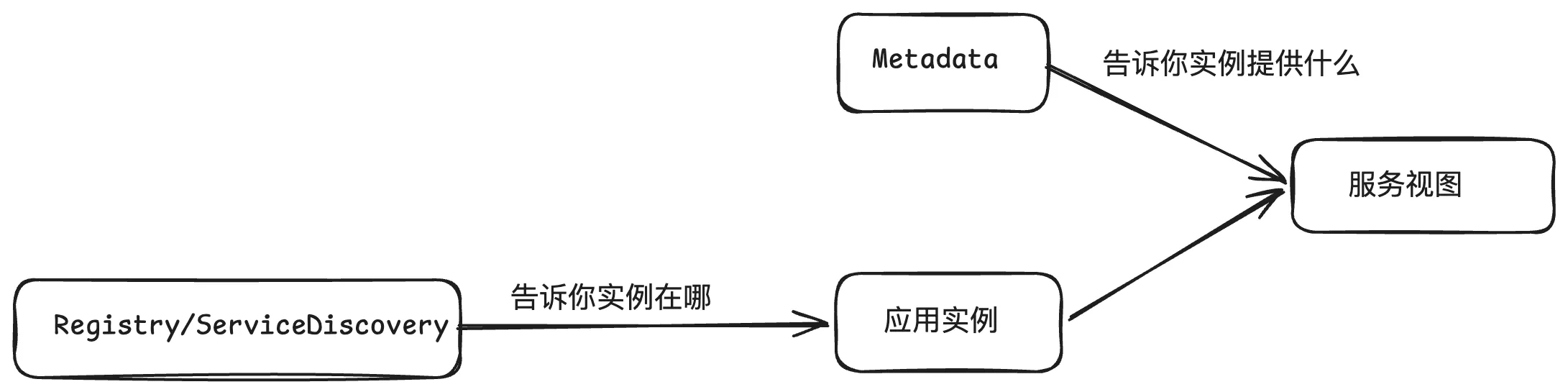
从架构上看 metadata 处在什么位置
如果只看 metadata/ 目录,很容易觉得它是一个相对独立的小模块。但从实际运行链路看,它和 config、registry、service discovery、protocol 这些模块都有很强的关系。
可以参考大致关系图:
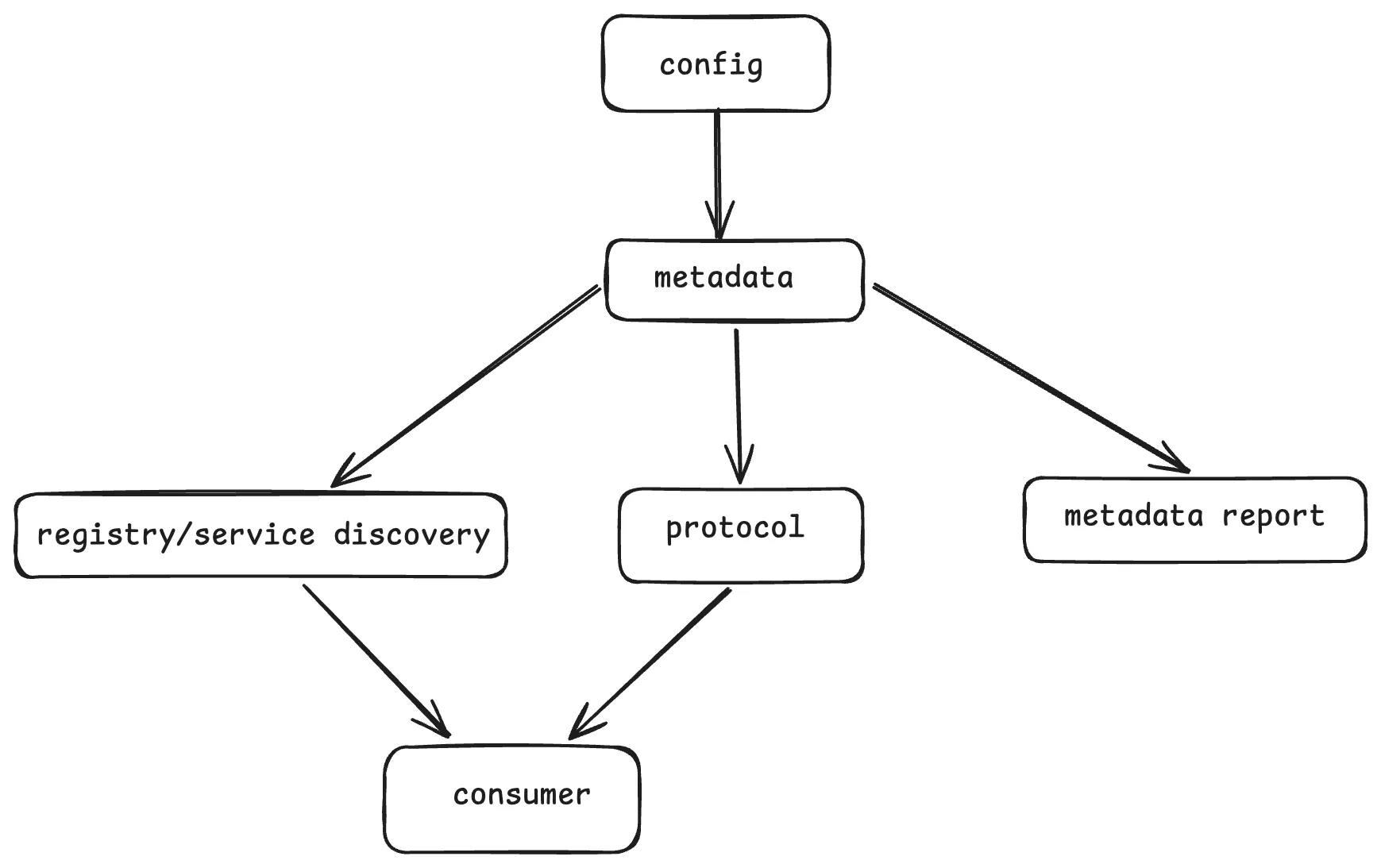
这分别对应了几层关系:
1.和 config 的关系:装配入口
metadata 不是运行到一半突然出来的,它是在应用启动、服务导出、实例注册这些阶段被装配进去的。
也就是说,它从一开始就不是外围能力,而是启动链路的一部分。
2. 和 registry / service discovery 的关系:发现与解释
注册中心负责把实例发现出来,但实例只是一层“地址事实”;真正把它解释成“服务能力”的,是 metadata。
所以可以把两者理解成一组分工:
service discovery负责发现实例metadata负责恢复服务语义
3. 和 protocol 的关系:元数据也可以被远程访问
在 3.0.x 当前实现里,metadata 不是只存在于中心存储里,provider 自己也会维护并暴露一个 MetadataService。这意味着 metadata 不只是“被保存”,它本身也是一种可以通过 RPC 获取的运行时能力。
4. 和 consumer 的关系:最终恢复调用视图
consumer 拿到的不是最终服务地址,而是一组应用实例。之后要靠 metadata 把这些实例重新还原成可调用的服务 URL。这也是 metadata 在运行时最直接的价值体现。
Dubbo-Go 3.0 中 metadata 具体做了什么
从宏观上看,3.0 的 metadata 主要做三件事。
1. 维护“应用当前暴露的服务集合”(核心)
一个应用启动后,到底提供了哪些服务,这些服务属于什么 group、version、protocol、path,有哪些方法,这些信息最终会形成一份应用级的 metadata 视图。
这份视图不是为了展示,而是为了让 consumer 在发现应用实例之后,仍然能够知道这个实例背后到底能调用哪些服务。
如果没有这层数据,应用级服务发现拿到的只会是一组裸实例地址,没办法直接支撑 Dubbo 的调用模型。
2. 给服务集合生成 Revision
3.0 里的 metadata 有一个非常关键的概念,叫 revision。
可以把它理解成:
当前导出服务视图的一份轻量摘要
在 3.0 当前实现里,它更接近对“接口 + 方法集合”的摘要,而不是对全部服务语义的强哈希。
所以更准确地说:
- 大多数服务集合变化会推动 revision 变化
- 但不是所有参数级、语义级变化都一定会反映到 revision 上
这件事的价值在于,它给了 consumer 一个轻量的判断依据:
- revision 没变,通常说明不需要重新拉取 metadata
- revision 变了,说明需要重新拉取 metadata
于是 metadata 不再是一份被动数据,而变成了一种可以被变化感知的运行时状态。

这个设计是把“实例变化”和“服务语义变化”真正连接了起来
3. 建立“接口 -> 应用”的映射
应用级服务发现里,注册中心认识的是应用;但 Dubbo 的消费模型,很多时候仍然是按接口订阅。
于是系统必须回答一个问题:
一个接口,到底属于哪些应用?
这就是 mapping 的意义。
provider 在导出服务时,会把“当前接口属于当前应用”这件事登记下来;consumer 在订阅服务时,先通过这层映射找到应用,再去监听这些应用实例的变化。
在 dubbo-go 3.0 的默认实现里,这层 mapping 不是纯本地能力,而是依赖 metadata report 来登记和查询。如果没有 metadata report,自动 mapping 能力就会受限,这时候通常要靠 provided-by 或 subscribed-services 这类显式信息兜底。

这一步看起来像是一个小功能,但实际上它是应用级发现和接口级调用之间最关键的桥。
如果没有它,consumer 就只能按应用消费,很难保持原本 Dubbo 习惯里的接口视角。
Metadata 是怎么串起 Provider 和 Consumer 的
如果从运行流程去看,3.0 的 metadata 不是单点功能,而是一条完整链路。
Provider 侧
provider 在导出服务时,不只是把地址注册出去,还会同时做这些事:
- 把导出的 URL 记录到本地 metadata
- 生成应用级服务集合视图
- 计算 revision
- 建立接口到应用的映射
- 在实例 metadata 中写入 revision、storage type、protocol endpoints、metadata 入口参数等信息
- 视情况把 app metadata 发布到远端 metadata center
这意味着 provider 不只是“发布服务”,还在同步维护一份服务语义快照。
不过 metadata 也不只有 provider 这一半状态。consumer 本地同样会维护订阅 URL 集合,并生成一份 subscribed revision,只是它在运行时最直接的价值,还是体现在“把应用实例恢复成服务视图”这条主路径上。
Consumer 侧
consumer 在订阅服务时,也不是直接从注册中心拿一组接口地址就结束了。它的过程更像这样:
- 先从接口出发
- 通过 mapping 找到对应应用
- 监听这些应用实例变化
- 收到实例后读取 revision
- 根据 revision 获取应用级 metadata
- 再把实例地址和 metadata 组合,恢复成最终服务 URL
所以从链路上看,metadata 的作用很像一个中间解释层:
- 上游接的是应用实例
- 下游产出的是服务视图
和 Dubbo-Java 3.3 相比还缺了什么
如果把 dubbo-go 3.0 放到更长的演进线上看,它的不足不在方向,而更多在成熟度和配套能力上。
也就是说,它已经实现了“应用级服务发现需要 metadata 这层语义补全”这个核心目标,但和 dubbo-java 3.3 相比,仍然有几块明显偏薄。
1. 元数据模型本身还不够丰富
dubbo-go 3.0 的 metadata 核心已经能表达“应用暴露了哪些服务”,也维护了一部分 consumer 侧订阅状态,这对 Go 侧落地应用级服务发现已经够用了。
但 dubbo-java 3.3 的 metadata 模型要更完整一些。它不只是维护 app + revision + services,还把更丰富的运行时内容一起纳进去了,比如原始 metadata 内容缓存、实例级参数、扩展参数、服务 URL 视图、参数过滤机制等。换句话说,Java 侧的 metadata 已经不只是“服务清单”,而更像“运行时元数据总视图”。
所以从模型成熟度上说,Go 3.0 更像是一个足够可用的核心版,而 Java 3.3 已经发展成更丰富的体系版。
2. MetadataService 的能力边界更窄
在 dubbo-go 3.0 里,metadata service 已经承担了关键职责,但它更偏向“围绕服务发现恢复所需的最小能力”。
而 dubbo-java 3.3 的 MetadataService 已经更像一个完整的元数据访问入口。除了基础的 metadata 查询,它还覆盖了多份 metadata 聚合、实例级 metadata 监听、metadata URL 获取、开放接口能力等。
这意味着 Java 侧的 metadata service 不只是供 consumer 恢复地址使用,也更方便运维、控制台、治理侧能力接入。Go 3.0 在这一点上还明显偏保守,能力更集中在“服务发现主路径”本身。
3. 实例级元数据表达能力偏弱
dubbo-java 3.3 在 service instance metadata 上已经做得比较细了,比如多协议 endpoint、metadata 版本、metadata cluster、实例级 customizer 等能力都比较完整。
相比之下,dubbo-go 3.0 的实例级 metadata 仍然偏“够用就好”。它已经包含 revision、storage type、protocol endpoints、metadata service url params 这类最小可运行字段,但在 metadata 版本、多协议细节、实例级元数据扩展这些方面,表达能力还没有 Java 那么细腻。
这类差异平时不一定立刻暴露,但一旦走到更复杂的注册发现场景、更多协议并存、或者治理侧能力增强的时候,差距就会变得明显。
4. 接口到应用映射的动态能力不够强
dubbo-go 3.0 已经有 service-app mapping,这一点非常关键,因为它让应用级发现和接口级订阅之间建立了桥。
但如果和 dubbo-java 3.3 相比,Go 3.0 这一层更多还是“能查到映射关系”,而 Java 3.3 已经把“映射变化监听、缓存、动态更新”这套机制做得更成熟。也就是说,Java 侧不仅能回答“现在是谁提供这个接口”,还更强调“如果这个映射关系变化了,系统怎么持续感知”。
从这一点看,Go 3.0 的 mapping 更像是第一代完整方案,而 Java 3.3 已经是更偏长期运行和治理视角的版本。
5. 缺少更成熟的迁移配套能力
这是和 dubbo-java 3.3 最明显的一类差异。
Java 3.3 围绕应用级服务发现已经形成了比较成熟的迁移机制,比如双注册、双订阅、register-mode、APPLICATION_FIRST / FORCE_APPLICATION 这类迁移和切流策略。它考虑的不只是“应用级发现怎么工作”,还考虑“旧模型怎么平滑迁到新模型”。
而 dubbo-go 3.0 的 metadata 虽然已经具备应用级发现的基础,但从整体上看,还没有形成 Java 那种成熟的迁移工具链。也就是说,它更像是在 Go 侧把新模型搭起来了,但还没有把机制做得像 Java 那么完整。
简单总结
dubbo-go 3.0 的 metadata,最大的价值在于它已经把应用级服务发现所必需的语义补全链路搭起来了。它回答了实例如何恢复成服务、接口如何映射到应用、服务变化如何被感知这些关键问题,因此它绝不是一个边缘模块,而是 3.0 服务发现设计中的核心一环。
但与此同时,它在模型丰富度、实例级 metadata 表达、动态映射、迁移机制和生态化配套上,还没有达到 dubbo-java 3.3 那种更成熟、更治理化的程度。